The API
In this project series, we’re going to build a REST API that exposes resources related to stocks. In this post, we’re going to precompute our technical SMA indicator for our clients to consume through our API.
You may find the code in the following repository:
Do We Need to Precompute Data?
Let’s say we had customers paying for our API. It would be in our best interest to keep the API as responsive and fast as possible. Let’s consider this endpoint:
- /api/v1/indicators/sma/{ticker}
What would be the best way to keep this endpoint responsive? Well, we could do the calculation on the fly as clients call the API. However, this has some drawbacks. Firstly, this would add load on our server since we’d be doing calculations on every request made. Think about cases where we had 10 users, 100 users, and 10000 users. If they are all hitting this endpoint, computing on the fly wouldn’t scale well. Additionally, some users might be requesting the same data, meaning that we’d be redoing calculations that we’ve already done.
A more sensible approach would be to precompute these technicals from our ticker data. That way, we would create a resource in which our API can query and simply return the data. Then, our API can focus on querying and retrieving the resources and we can build other processes that can focus on precomputing and building the actual API resources.
Simple Moving Average
In our Demo project, we’re going to create simple moving averages (SMA) with varying precomputed windows. We’ll do 5, 10, 20, 50, 100, and 200 moving averages on the closing prices of our stock data. Then, our API can allow the client to specify a stock, date range, and SMA. From there, the API simply needs to query the database and retrieve the data.
So, the new endpoint becomes:
- /api/v1/indicators/sma/{ticker}
- from_date
- to_date
- sma_window
Precomputing the SMAs
To compute our SMAs we’ll use the following function:
def calculate_sma(data, period):
"""
Calculate the Simple Moving Average (SMA) for the given data.
:param data: A list of dictionaries containing 'date' and 'close' prices.
:param period: period used to calculate sma.
:return: A list of dictionaries with an additional 'SMA' key.
"""
close_prices = [entry['close'] for entry in data]
sma_values = []
for i in range(len(close_prices)):
if i + 1 < period:
sma_values.append(None)
else:
sma = sum(close_prices[i + 1 - period:i + 1]) / period
sma_values.append(sma)
for i in range(len(data)):
data[i]['SMA'] = sma_values[i]
return data
A simple moving average allows us to see general trends on the closing price of the stock, which helps to smooth the data. Looking at daily closing price can be messy since it’s volatile. Looking at a smoothing average across different windows allows us to see the general trends.
Recall that our datbase has around 25 million rows of data, so doing the precompuation on your PC might take some time. With one thread, this took roughly 4 hours to compute on my PC. In another blog post, we’ll explore some techniques using workers, which can drastically reduce this time by processing the data in parallel on separate threads and machines.
This is an example of our precomupted data for 5, 20, 50, 100, and 200 day SMA indicators.
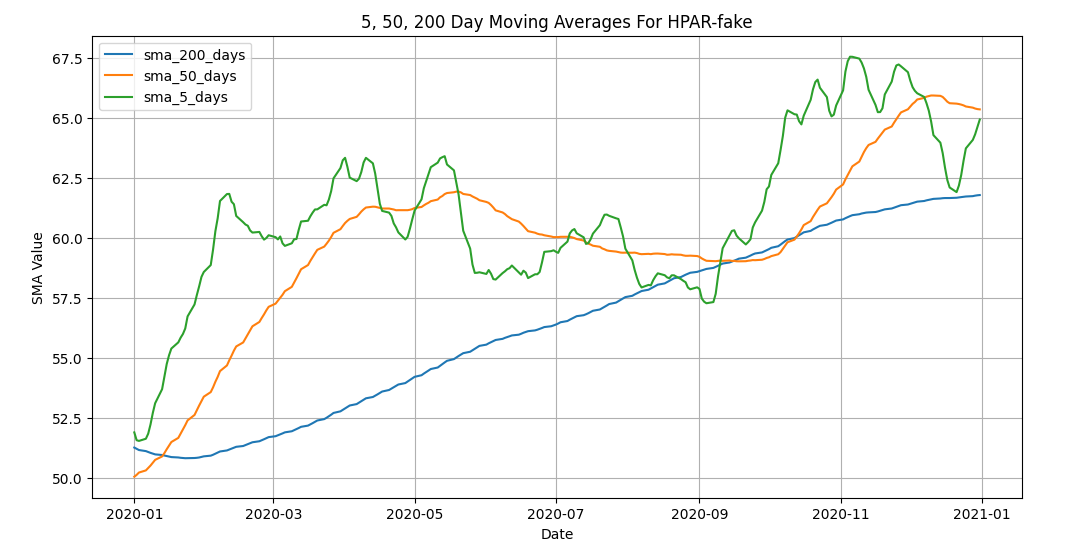
You can see from our chart, why an SMA might be valuable. From our generated data, you can see that by increasing the window or period of the SMA, that the trend is smoothed by removing the noise in the data.
Next Steps
So far, we have precomputed the 5, 10, 20, 50, 100, and 200 day SMAs for ALL tickers in our database across all dates. This took several hours on one machine (we’ll look at ways to improve this in a later post) but we now have a computed resource in which a client can consume via an API. The advantage here is that our API can simply query this data, rather than doing calculations on the fly. This will enable us to make our API quick and efficient for clients, while our backend processes handle the heavy lifting with the number crunching!
Next, we’ll build our API layer to expose these SMA resources via a simple RESTful API.